Thanks to one of my best clients, this article has been recovered in full after the data loss
While working with a client recently, I had a situation where they had two non-HA cubes connecting to two VeloCloud SDWAN devices to get to the carrier. My first thought was to use OSPF for the routes which would allow for easy failover and a potential use of BFD. However, the carrier informed us that they only use dynamic routing protocols on their upstream connections, and we would need to use static routes to them.
My first thought in this case (barring bad thoughts about the carrier) were just using weighted static routes and relying on if the carrier’s interface is down, we would see it down causing the secondary static route to take over. Well, after testing with the carrier, if they shut their port, Cisco saw it up up resulting in 100% packet loss due to the lack of transition for the static route. See the routes below


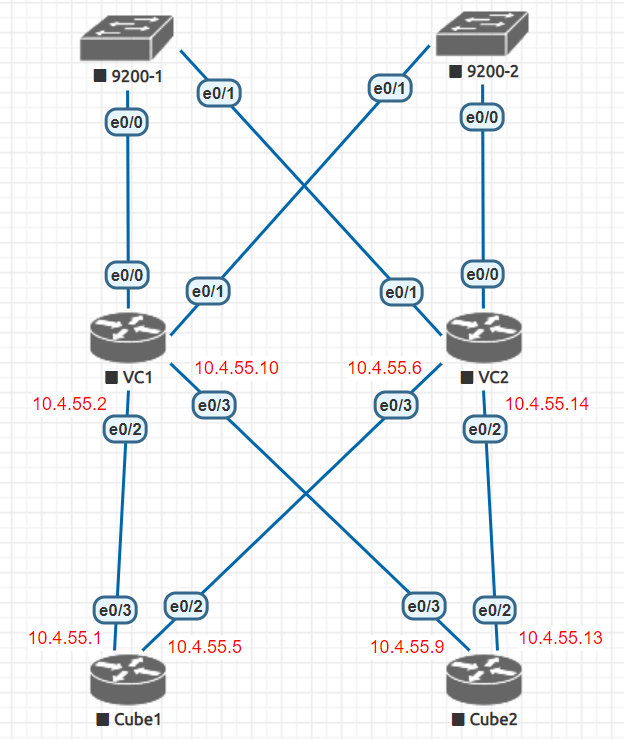
In this case, the solution was to use IP SLA. My configuration was pretty basic initially, as shown below.


Very simple IP SLA setup here, basically, I have a ping going to a specific IP address on the distant end. If that IP stops responding to pings, the static route through 10.4.55.2 drops and we go through 10.4.55.6. This worked perfectly, until it was time to fall back to the primary route. The issue? There was no route over the primary path to see if the IP was reachable!
To correct this, we needed a static route that wouldn’t go away if the reachability was down. In newer Cisco IOS, there is a “permanent” command for static routes which does just that. The route will ALWAYS stay in the table. So, you’re thinking, ok wouldn’t that stop your backup route from working? Well, in this case we will just use a /32 to the destination ip. It’s not an IP we need to talk to normally and it’s pingable IN the carrier’s network rather than outside of it so it provides good consistent behavior.
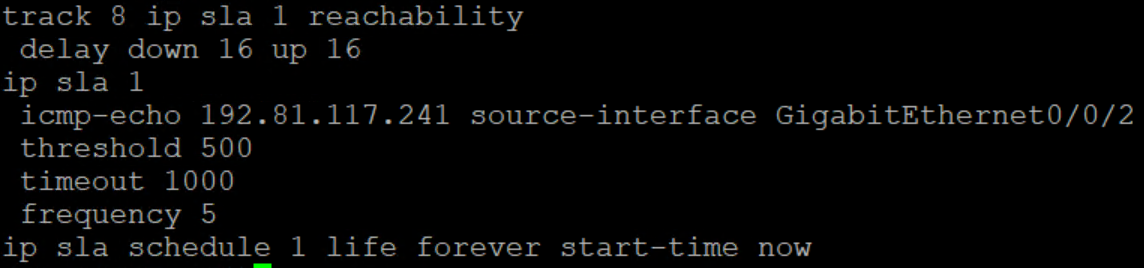


This worked out pretty well. You can see that the /24 route is going out 10.4.55.2 as intended. For testing, I had the carrier shut their side of the interface pointing to my e0/2. Cube1 showed this interface as up up. Here is what happened:
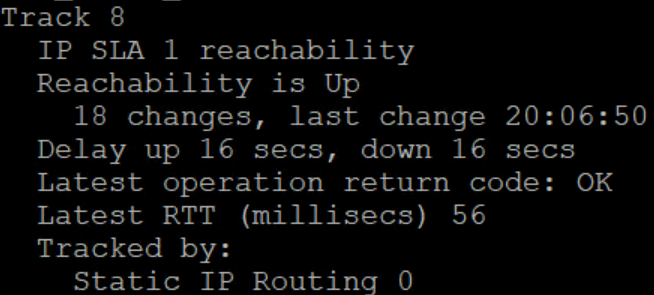
What we see here is that the IP SLA detected the interface was down, even though it appears up. Due to the 16 second delay (for stability) it immediately starts routing across the other link but is ready to move back instantly if it were to pop back up. When that delay expires, we see
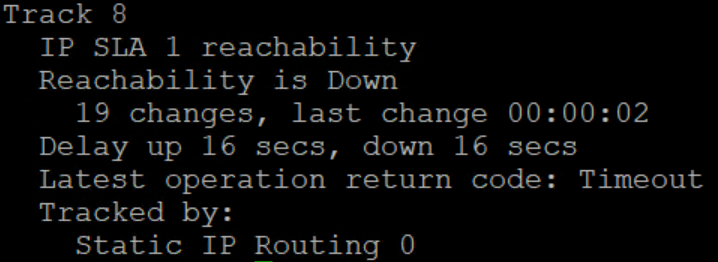

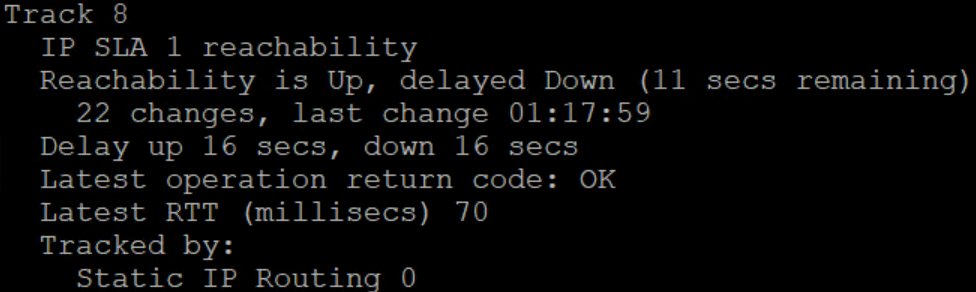
Here we can see that the /24 is routing via 10.4.55.6, but the ping is taking the /32 for the 192.81.117.241 we’re using to establish up/down state across 10.4.55.2. That means that ping will ONLY use 10.4.55.2 so once it starts replying again, we will see
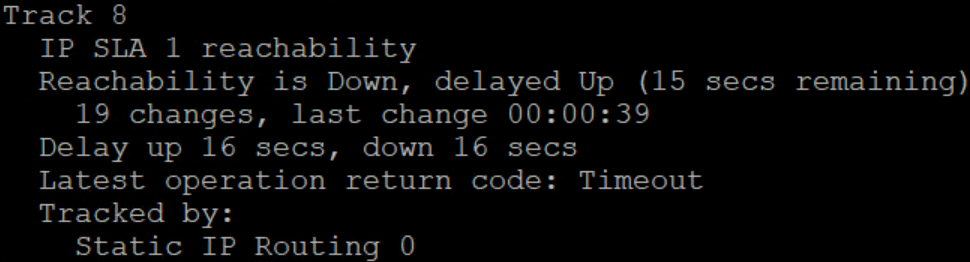
Once again, we see the delay. This is some protection against an unstable connection coming up. We won’t fully swap until that 15seconds passes which should show us the link is relatively stable. If e0/3 went down during this though, traffic would immediately route across e0/2 even though the delay up wasn’t completed.
Now that we’re stable, we see the following
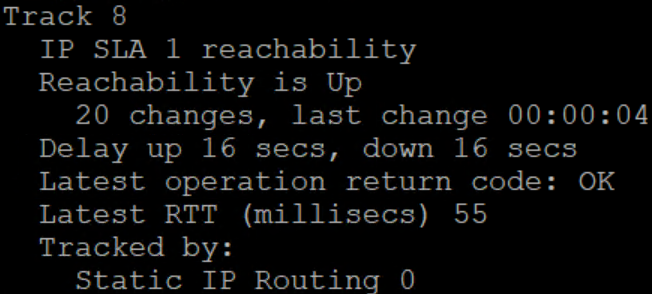
I hope this was informative. It was quite the adventure to get this working for my client. As explained, this is for voice traffic so was pretty important it works right. Our next steps are to setup redundancy groups on the 4321 cubes to ensure voice preservation during outages.